Predicting CBT fidelity like a human
Here at Lyssn, we are constantly working to create tools that use AI to improve the quality of mental health services at scale and help support therapists in their development of skills. So, we were very excited to release our first version of an automated CBT fidelity rating tool last spring. The software takes an audio recording of a therapy session and rates it on the Cognitive Therapy Rating Scale (CTRS) in about 5 minutes — a process that normally takes a highly-trained human rater several hours, if you have access to one (and of course costs a whole lot of $). In the last few months, we have updated our machine learning models that provide automatic CBT fidelity ratings, and we have seen major improvements. (And when I say major, I mean unbelievably better).
Nerdy experimental details
First, let me explain a little about how we do these experiments. At Lyssn, when we build a model to predict therapy evaluations that are normally done by a human, we first need a large dataset of human-rated sessions. For this research, we collaborated with Lyssn advisor Dr. Torrey Creed at the University of Pennsylvania and rated sessions that came from community settings rather than academic contexts. We divide these sessions into three groups: (1) a training set (data that is used to train the model), (2) a validation set (data that is used to guide us in model tuning), and (3) a test set (a bunch of sessions that we don’t touch or look at until the end when we want to see how our models perform on an unseen group of sessions). All of the results reported here are on the test set. We then compare our model performance to how much human raters agree with each other. Human-to-human reliability is more or less the ceiling in these kinds of tasks. The chart below is showing how close our model is to an average human rater.
Extra nerdy footnote: We scored our models and interrater reliability using a Spearman correlation, which compares how two different raters order a set of scores. We use this instead of a pearson correlation because some of these scales can be skewed a bit, or sometimes have a restricted range.
How did we do it?
So here is the thing: Dave Atkins (Lyssn CEO) is going to stop sending me my favorite whiskey if I tell you everything, but here is what I can share. Older techniques in Natural Language Processing (NLP) approached every new task like they didn’t know anything about the English language. We all knew this was a problem, but no one yet understood how to leverage pre-existing knowledge of a language to improve performance on new tasks. (This is a wild generalization — there are definitely exceptions — but I think this is broadly true). Recently, the NLP community has figured out how to build models that learn how to replace missing words from huge datasets, and these models can be fine-tuned to do amazing things. Now, the devil is in the details, you have to sometimes get creative to figure out how to make these models work with very large inputs (like an entire therapy session). For session-level variables, we built a model called the Lyssn Transformer to solve some of the challenges around classifying long text documents.
Want to learn more about NLP? Here is an article that we wrote with friends of Lyssn a few years ago outlining applications of NLP to psychotherapy data. For a deeper dive, here is a seminal article by some of the pioneers of NLP work.
What did we find?
For most of the individual items on the CTRS — and, importantly, the total score — our model is indistinguishable from an average human rater. I know. As an NLP researcher, I have a hard time getting my head around that as well. When I work on these difficult, subtle human rating tasks, I don’t typically think of them as problems that we are going to completely solve. (I’m normally just hoping to get close). In short, these results are pretty wild. This is just one example of a new set of techniques that we are using at Lyssn that are going to have a major positive impact on everything we predict. Those of you who are following closely probably noticed our 50% reduction in word error rate in the automatic speech recognition engine — that improvement was from some of the same tricks we used here.
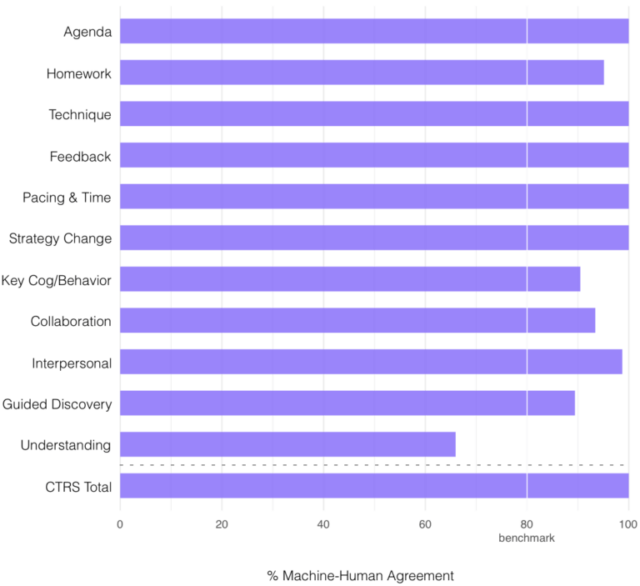
So what does this mean? If you are a clinician practicing CBT, you would be lucky if one or two sessions in your entire career were scored for CBT fidelity by an expert rater. Now, with Lyssn you can score every single session over the course of a week or month. If you are a supervisor, you can view the CBT metrics of your entire clinic on a daily, weekly or monthly basis. You can examine each of the 11 CTRS criteria to assess what aspects of your practice are hitting the mark and what might need improvement. This is the type of reflective practice we hope to facilitate at Lyssn.
This is what we love to do
One of our goals at Lyssn is to support clinicians’ work by making feedback faster, more detailed, actionable, and reliable. The process to obtain feedback, whether CBT or other evidence-based treatments, is nearly unattainable for most clinicians. We believe feedback is so helpful to develop one’s clinical practice that it should be available to anyone who wants it. Many of us at Lyssn are clinicians who were fortunate enough to receive helpful feedback during our clinical training and experience firsthand its impact on developing a reflective clinical practice.
That said, it is important for the clinician using Lyssn to trust and understand these metrics. To help build that trust, we aim to be transparent about how well our platform works. If we can’t predict something well, we are going to tell you. Feedback is only as good as the science behind it. Many years of research and development have gone into building the Lyssn platform and we’ve succeeded (and sometimes failed) at solving many hard problems. But that’s what makes the work so much fun. The idea that a machine can rate a CBT session at the same level as a human is pretty astounding and we are excited to share these results and make them readily available to support clinicians’ work.
We’ll continue to keep you updated in the future and if you have any questions or thoughts please feel free to drop us a note at contact@lyssn.io!